Kiitos paljon ameebaa rivipainoja koskevasta oivalluksesta. Tiedän, että tämä ei ole päällekytkentä, mutta minulla oli vaikeuksia löytää rivipainotetun PCA: n toteutus selityksineen, ja koska tämä on yksi ensimmäisistä tuloksista painotettua PCA: ta googlattaessa, ajattelin, että olisi hyvä liittää ratkaisuni , ehkä se voi auttaa muita samassa tilanteessa. Tässä Python2-koodinpätkässä PCA: ta, joka on painotettu edellä kuvatulla RBF-ytimellä, käytetään 2D-tietojoukon tangenttien laskemiseen. Olen iloinen kuullessani palautetta!
def weighted_pca_regression (x_vec, y_vec, painot):
"" "
Annetaan kolme reaaliarvotettua yhtä pitkää vektoria, jotka vastaavat koordinaatteja
2-ulotteisen tietojoukon ja painon mukaan tämä toiminto antaa kulman radiaaneina
linjan (painotetun) keskiarvon ja lineaarisen pääkomponentin kanssa
tiedot. Tätä varten lasketaan ensin painotettu keskiarvo ja kovarianssimatriisi.
Sitten suoritetaan u, e, v = svd (cov) ja u * f (x) = 0 ratkaistaan.
"" "
input_mat = np.pino ([x_vec, y_vec])
painot_summa = painot.sum ()
# Vähennä (painotettu) keskiarvo ja laske (painotettu) kovarianssimatriisi:
mean_x, mean_y = weights.dot (x_vec) / weights_sum, weights.dot (y_vec) / weights_sum
keskitetty_x, keskitetty_y = x_vec-keskiarvox, y_vec-keskiarvo_y
matrix_centered = np.pino ([keskitetty_x, keskitetty_y])
painotettu_kov = matriisi_keskitetty.dot (np.diag (painot) .dot (matriisi_keskitetty.T)) / painojen_summa
# Tiedämme, että v kiertää datan pääkomponentin y = 0-akselille ja
# että u kiertää sitä takaisin. U.dot ([x, 0]) = [x * u [0,0], x * u [1,0]] ratkaisemalla saadaan
# f (x) = (u [1,0] / u [0,0]) x rekonstruoituna funktiona.
u, e, v = np.linalg.svd (painotettu_kov)
palauta np.arctan2 (u [1,0], u [0,0]) # arctan vakaampi kuin jakaminen
# KÄYTTÖESIMERKKI:
# Määritä ydin ja tee ellipsi regressiolle:
rbf = lambda vec, stddev: np.exp (-0,5 * np.power (vec / stddev, 2))
x_span = np.linspace (0, 2 * np.pi, 31) +0,1
data_x = np.cos (x_span) [: - 1] * 20-1000
data_y = np.sin (x_span) [: - 1] * 10 + 5000
data_xy = np.pino ([data_x, data_y])
stddev = 1 # 1: n stddev on tässä yhteydessä erittäin paikallista
keskukselle data_xy.T:
# paino pisteet niiden euklidisen etäisyyden perusteella nykyiseen keskukseen
euklidiset etäisyydet = np.linalg.norm (data_xy.T-keskus, akseli = 1)
painot = rbf (euklidiset etäisyydet, stddev)
# saat regressiokulman radiaaneina
p_grad = painotettu_pca_regressio (data_x, data_y, painot)
# juoni havainnollistamista varten
line_x = np.linstila (-5,5,10)
viiva_y = np.tan (p_grad) * viiva_x
plt.plot (viiva_x + keskiö [0], viiva_y + keskiö [1], c = "r")
plt.scatter (* data_xy)
plt.show ()
Ja näyteuloste (se tekee saman jokaiselle pisteelle):
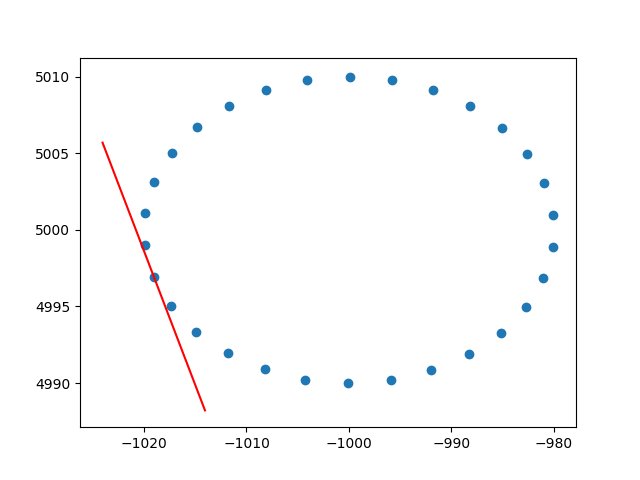
Kippis,
Andres